About (Siru Zhong 钟嗣儒) PhD @ HKUST(GZ), Visiting @ THU & NSCS · Spatio-Temporal Intelligence · Beta Infinity · ex-Huawei / XPeng / Tencent

Hi there, I'm Siru Zhong, a Ph.D. Candidate at The Hong Kong University of Science and Technology, Guangzhou, advised by Prof. Yuxuan Liang and Prof. Yang Yue. I also hold visiting affiliations with Tsinghua University and the National Supercomputing Center in Shenzhen, hosted by Prof. Haohuan Fu. My research focuses on Spatial-Temporal Intelligence, Time Series, and AI4Science.
I am honored to be a consecutive recipient of the HKUST (GZ) DSA Excellent Research Award, a Tutorial Speaker for MM4ST @ MM 2025 & ICME 2026 and MM4TS @ AAAI 2026, a Web Master for WebST 2025 & UrbComp 2025, and a reviewer/PC member for top venues including NeurIPS, ICLR, KDD, ACM MM, AAAI, PAKDD, IEEE TPAMI, FARS, MILETS, IJITDM, and Neurocomputing.
Beyond academia, I have sufficient industry experience. Currently, I work on Spatio-Temporal Memory in Embodied AI with Dr. Wulong Liu at Beta Infinity (2026). Previously, I worked on Spatio-Temporal Foundation Models deployed at scale at Huawei (2025), visual perception for autonomous driving at XPeng Motors (2024), and large-scale workflow data stream engineering at Tencent (2021–2023).
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Tsinghua University & National Supercomputing Center (SZ)Visiting PhD Student, HPGC Research GroupFeb. 2026 - Present
Tsinghua University & National Supercomputing Center (SZ)Visiting PhD Student, HPGC Research GroupFeb. 2026 - Present -
 The Hong Kong University of Science and Technology (GZ)PhD, Data Science and AnalyticsFeb. 2025 - Jan. 2028
The Hong Kong University of Science and Technology (GZ)PhD, Data Science and AnalyticsFeb. 2025 - Jan. 2028 -
The Hong Kong University of Science and Technology (GZ)MPhil, Data Science and AnalyticsAug. 2023 - Jan. 2025
-
 Hefei University of Technology (HFUT)BE, School of Artificial IntelligenceSep. 2018 - Jun. 2022
Hefei University of Technology (HFUT)BE, School of Artificial IntelligenceSep. 2018 - Jun. 2022
Experience
-
 Beta Infinity (Embodied Memory Team)Research Intern, Spatio-Temporal Memory in Embodied AIJun. 2026 - Present
Beta Infinity (Embodied Memory Team)Research Intern, Spatio-Temporal Memory in Embodied AIJun. 2026 - Present -
 Huawei (2012 Laboratories)Research Intern, Spatio-Temporal Foundation ModelsFeb. 2025 - Dec. 2025
Huawei (2012 Laboratories)Research Intern, Spatio-Temporal Foundation ModelsFeb. 2025 - Dec. 2025 -
 XPeng Motors (Autonomous Driving Center)Research Intern, Visual Perception for Autonomous DrivingMay. 2024 - Nov. 2024
XPeng Motors (Autonomous Driving Center)Research Intern, Visual Perception for Autonomous DrivingMay. 2024 - Nov. 2024 -
 Tencent (Workflow Data Center)Software Engineer (Full-time), Large-Scale Data Stream EngineeringJun. 2022 - May. 2023
Tencent (Workflow Data Center)Software Engineer (Full-time), Large-Scale Data Stream EngineeringJun. 2022 - May. 2023 -
Tencent (Workflow Data Center)Software Intern, Event Series OrchestrationJun. 2021 - Sep. 2021
Service
-
Reviewer: NeurIPS 2026; ICLR 2025, 2026; KDD 2026, 2027; AAAI 2027; ACML 2026; MM 2025; FARS (Fully Automated Research System); IEEE TPAMI; IEEE Neurocomputing; IJITDM
-
PC Member: ACM MM 2026; AAAI 2026; PAKDD 2026; MILETS 2026 @ KDD 2026
-
Tutorial Speaker: MM4ST @ MM 2025, MM4ST @ ICME 2026, MM4TS @ AAAI 2026
-
Web Master: WebST 2025, UrbComp 2025
Teaching
-
DSAA60000 Table Representation LearningSpring 2026
-
PLED5001 Communicating Research in EnglishSpring 2025
-
PDEV6800 Introduction to Teaching and Learning in Higher EducationFall 2024
Awards
-
Junior Student Track Awardees of DSA Excellent Research Award, HKUST(GZ)2026
-
Runner-Up Prize for DSA Excellent Research Award, HKUST(GZ)2025
-
Best Project Award (1st/15) in Data Science Computing, HKUST(GZ)2023
-
Outstanding Student (Top 10%) in Red Bird Summer Camp, HKUST(GZ)2023
-
iCode Certification of R&D Engineering Competency Evaluation, Tencent2022
-
Silver Award (2nd/12) in Code World Program, Tencent2022
-
Outstanding Student Award (8th/100) in New Employee Training, Tencent2022
-
Outstanding Graduation Thesis Award (Top 2%), HFUT2022
-
First Prize (Top 10) in CSDN Technology Blogger Competition2020
News
Publications (view all )
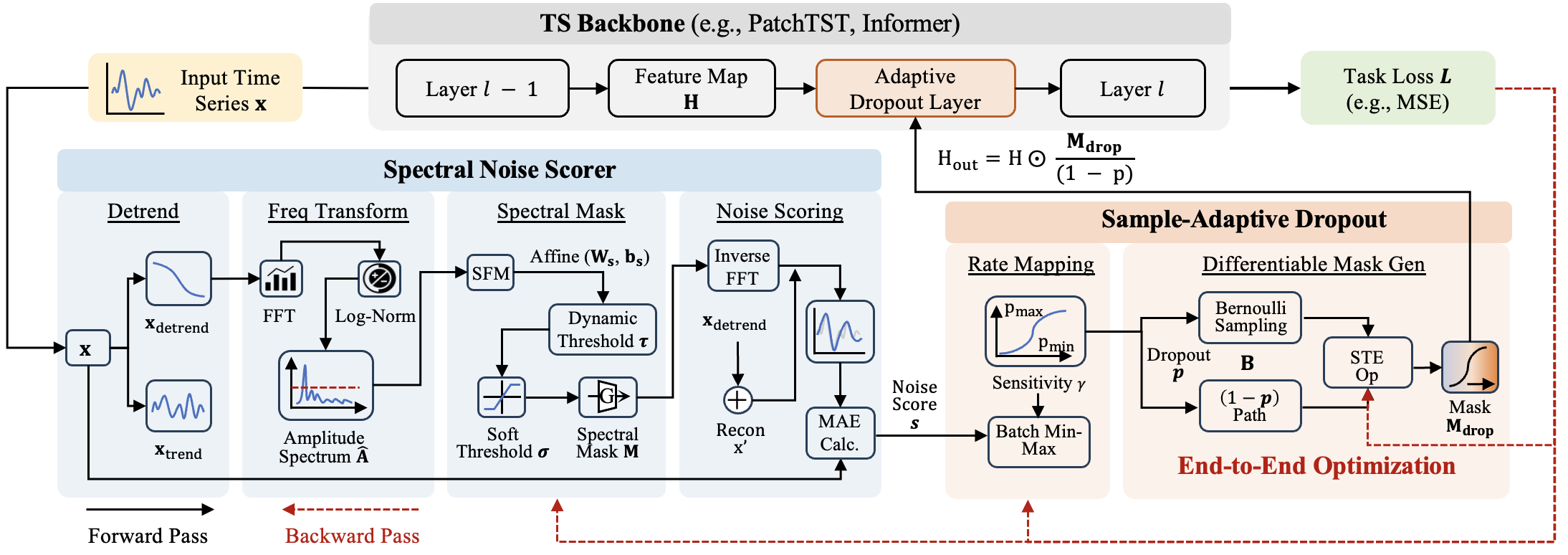
DropoutTS: Sample-Adaptive Dropout for Robust Time Series Forecasting
Siru Zhong, Yiqiu Liu, Zhiqing Cui, Zezhi Shao, Fei Wang, Qingsong Wen, Yuxuan Liang
ICML (International Conference on Machine Learning) 2026, Seoul, South Korea
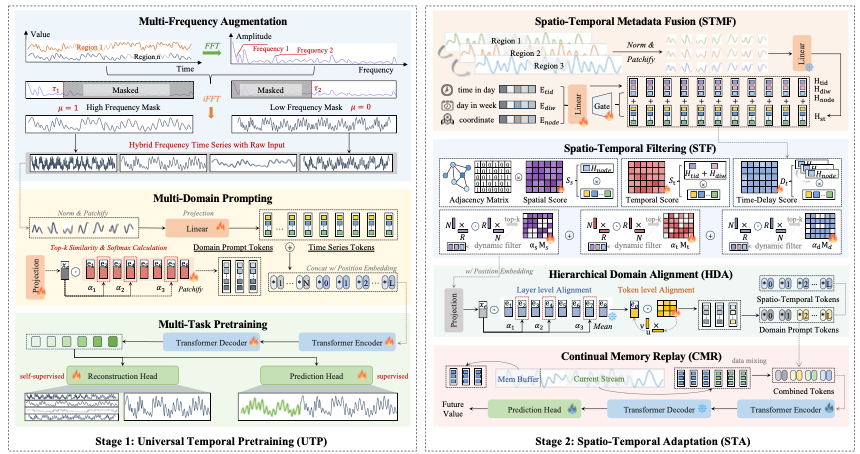
Learning to Factorize Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Xingchen Zou, Zhongwen Rao, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang
NeurIPS (Advances in Neural Information Processing Systems) 2025, Santiago, America Spotlight (688/21,575, 3.19%)
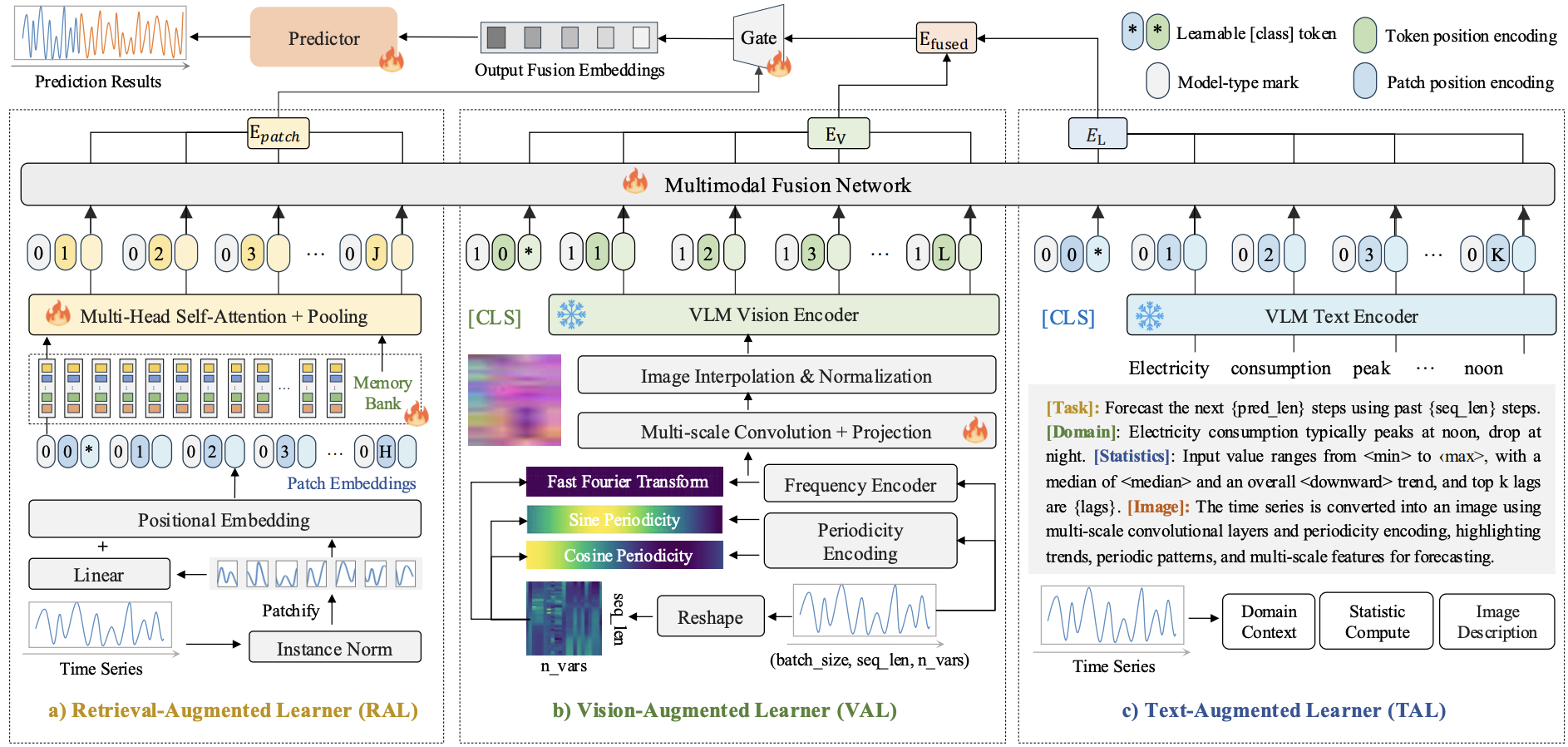
Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting
Siru Zhong, Weilin Ruan, Min Jin, Huan Li, Qingsong Wen, Yuxuan Liang
ICML (International Conference on Machine Learning) 2025, Vancouver, Canada
[Code] [Paper] [时序大模型] [大头的算法笔记] [时序量化Top] [时序前沿研究] [当交通遇上机器学习] [圆圆的算法笔记]

Multimodal Learning for Spatio-Temporal Data Mining
Siru Zhong, Xixuan Hao, Hao Miao, Yan Zhao, Oingsong Wen, Roger Zimmermann, Yuxuan Liang
ACM MM (ACM International Conference on Multimedia) 2025, Dublin, Ireland
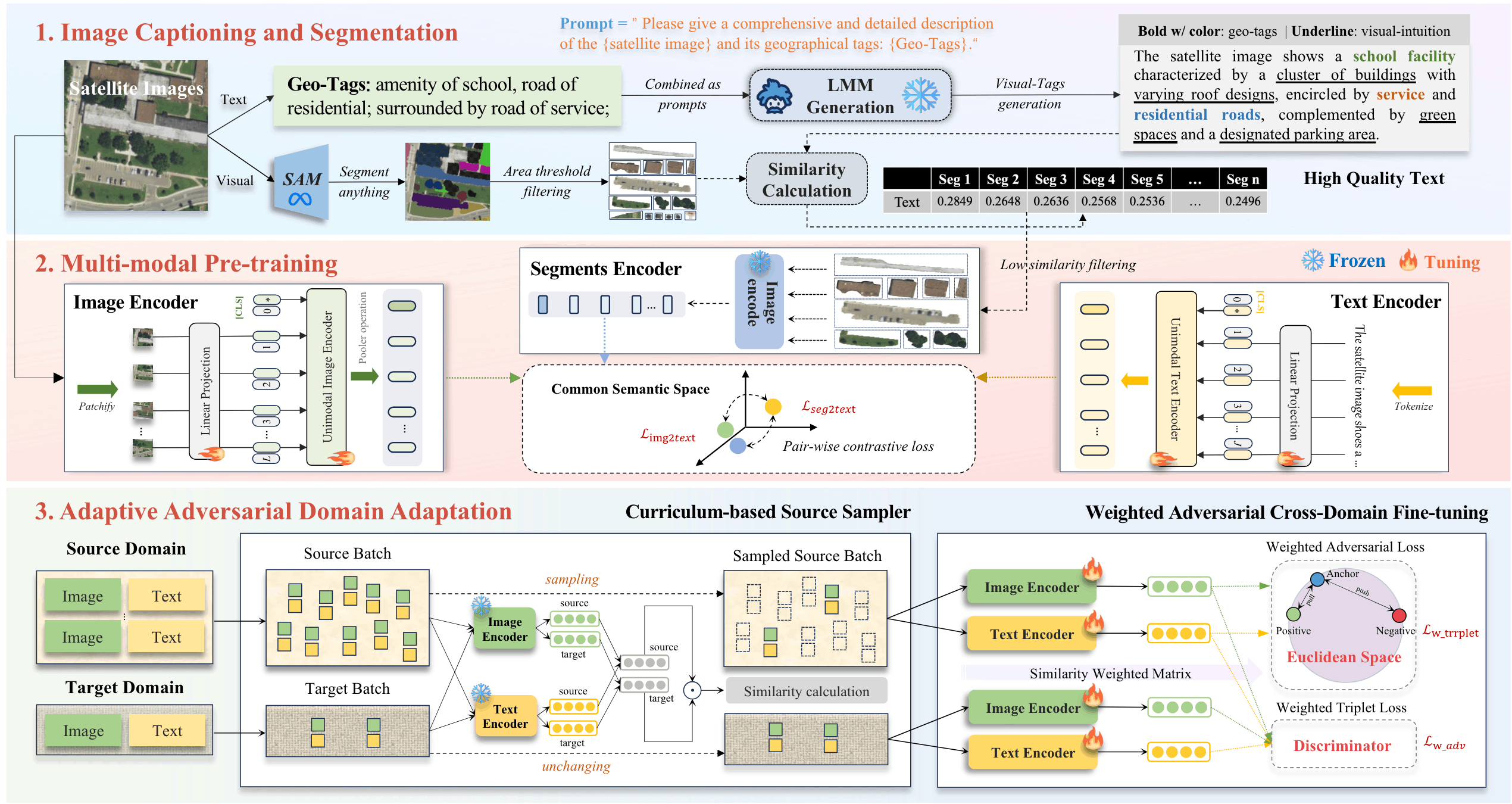
UrbanCross: Enhancing Satellite Image-Text Retrieval with Cross-Domain Adaptation
Siru Zhong, Xixuan Hao, Yibo Yan, Ying Zhang, Yangqiu Song, Yuxuan Liang
ACM MM (ACM International Conference on Multimedia) 2024, Melbourne, Australia
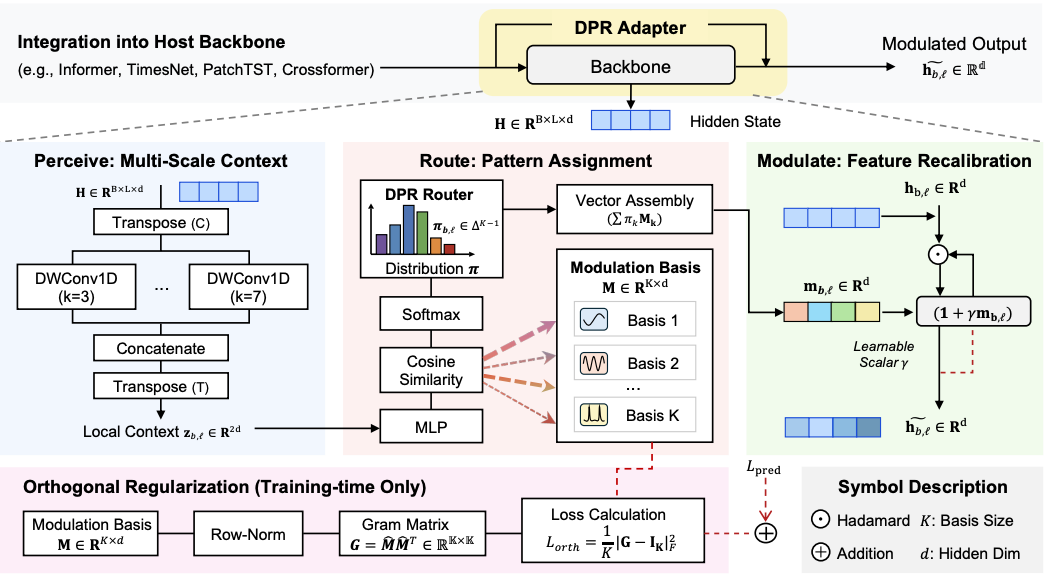
Perceive, Route and Modulate: Dynamic Pattern Recalibration for Time Series Forecasting
Siru Zhong, Meng Zhao, Haohuan Fu, Haoyang Li, Qingsong Wen, Yuxuan Liang
Under review.
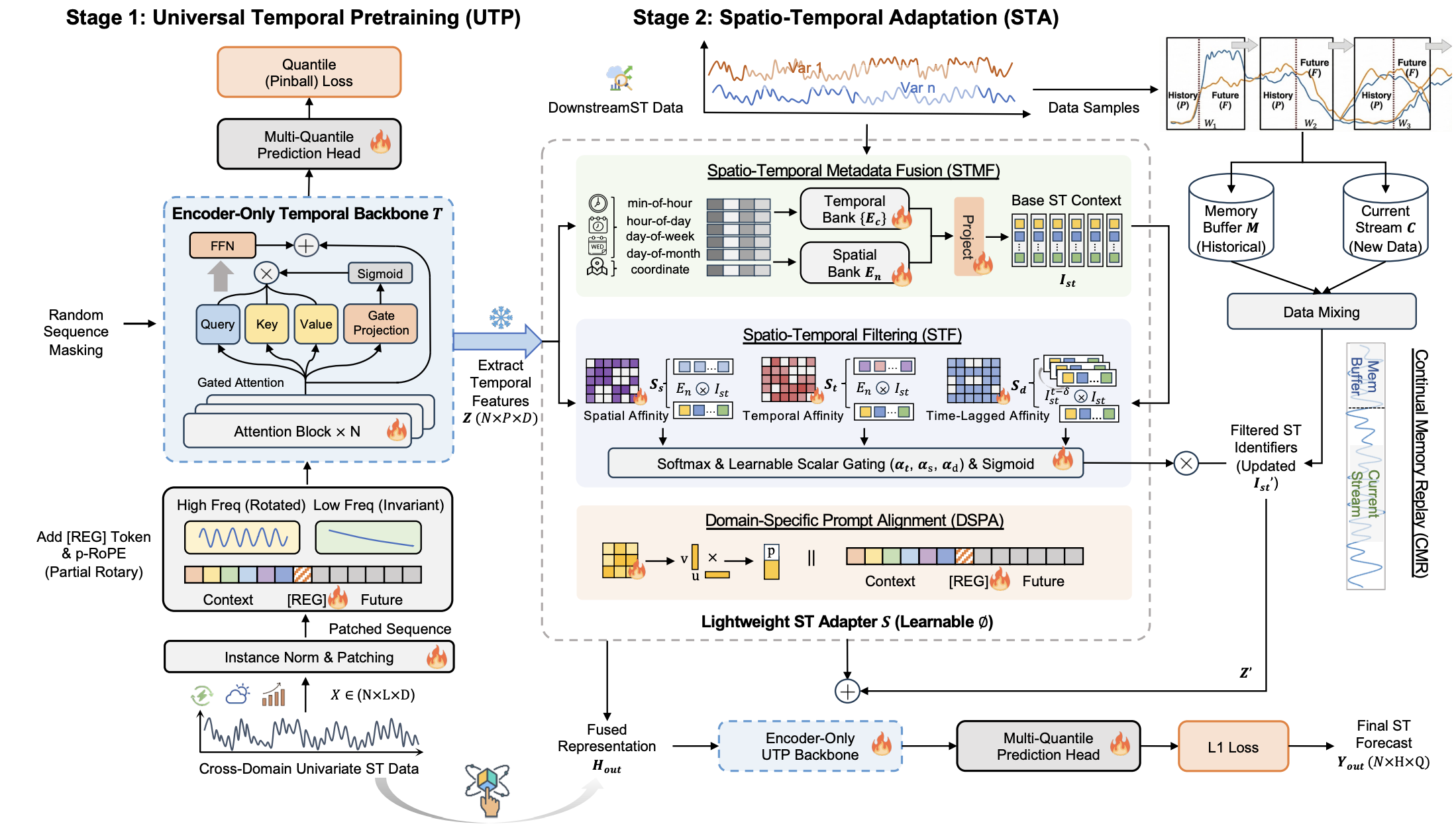
Learning to Factorize and Adapt: A Versatile Approach Toward Universal Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Yiqiu Liu, Yuanpeng He, Zhongwen Rao, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang
Under review.
Talks
-
跨时空学习:多模态感知、跨域泛化与鲁棒适应 [link]中南大学计算机学院第六届青年学者论坛, 长沙2026.07
-
DropoutTS: Sample-Adaptive Dropout for Robust Time Series Forecasting [link]AI TIME × ICML 2026, Online2026.06
-
Multi-modal TS Analysis: Methods, Datasets, and Applications [link]AAAI 2026 Tutorial, Singapore2026.03
-
Learning across Space and Time: Multimodal Integration, Foundation Models, and Dynamic Networks清华大学深圳国际研究院, 深圳2026.03
-
Multimodal Learning for Spatio-Temporal Data Mining [link]ACM MM 2025 Tutorial, Dublin2025.12