
I am a Ph.D. student at CityMind Lab, Hong Kong University of Science and Technology (GZ), supervised by Prof. Yuxuan Liang, Prof. Yue Yang, and Prof. Yangqiu Song. I am also a visiting Ph.D. student at HPGC Research Group, Tsinghua University, supervised by Prof. Haohuan Fu, and a visiting scholar at the National Supercomputing Center, Shenzhen. Previously, I obtained my M.Phil. from HKUST (GZ) and B.E. from Hefei University of Technology.
My research focuses on Time Series Modeling, Spatio-Temporal Data Mining, and AI4Earth. I also collaborate with Dr. Qingsong Wen @ Squirrel AI, Prof. Roger Zimmermann @ National University of Singapore, Prof. Zezhi Shao @ Chinese Academy of Sciences, and Prof. Shirui Pan @ Griffith University. Earlier, I interned at Huawei (supervised by Dr. Hao Xu), XPENG (supervised by Dr. Cheng Lu), and worked as a software engineer at Tencent (2022–2023).




I am passionate about building adaptive and practical spatio-temporal systems, translating research into deployable solutions that address real-world challenges.
Feel free to reach out via email if you're interested in discussing research ideas or exploring potential collaborations!
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "News
Publications (view all )
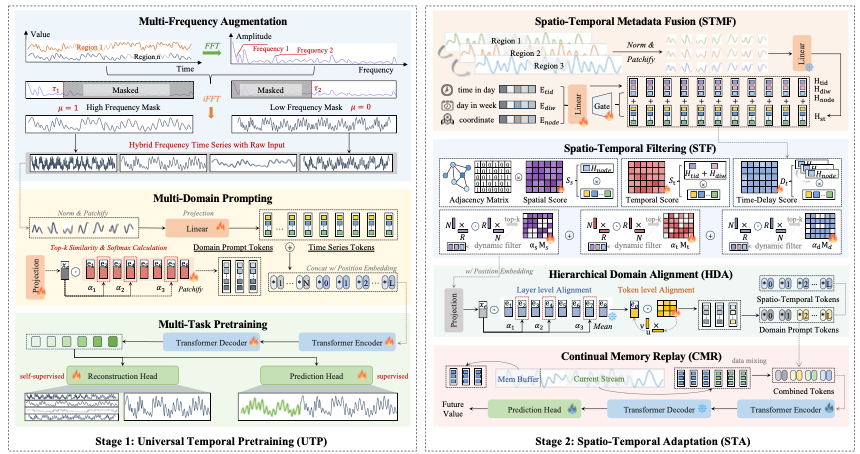
Learning to Factorize Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Xingchen Zou, Zhongwen Rao, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang
NeurIPS 2025, Santiago, America Spotlight (688/21,575, 3.19%)
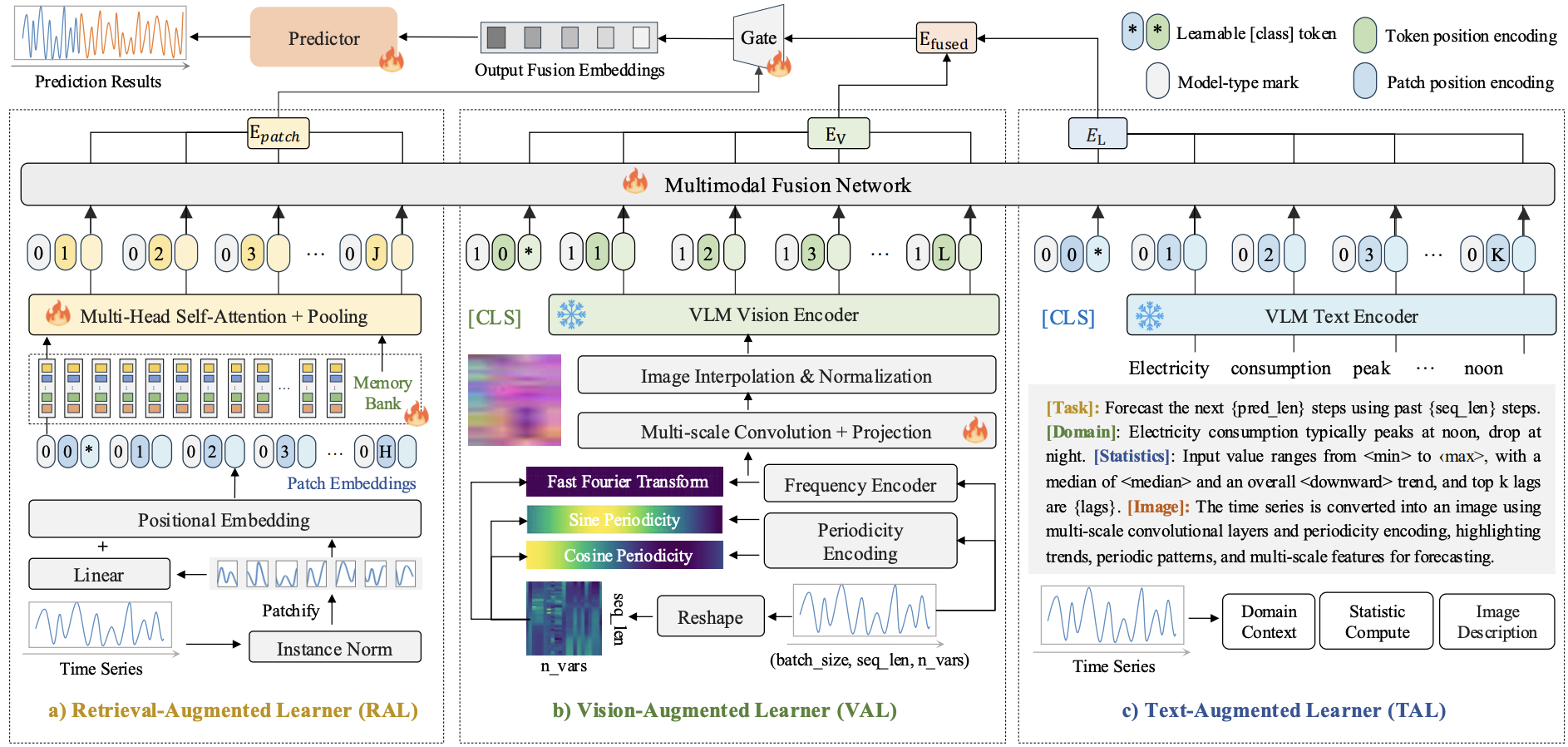
Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting
Siru Zhong, Weilin Ruan, Min Jin, Huan Li, Qingsong Wen, Yuxuan Liang
ICML 2025, Vancouver, Canada Poster
[Code] [Paper] [时序大模型] [大头的算法笔记] [时序量化Top] [时序前沿研究] [当交通遇上机器学习] [圆圆的算法笔记]

Multimodal Learning for Spatio-Temporal Data Mining
Siru Zhong, Xixuan Hao, Hao Miao, Yan Zhao, Oingsong Wen, Roger Zimmermann, Yuxuan Liang
MM 2025 Tutorial, Dublin, Ireland Tutorial
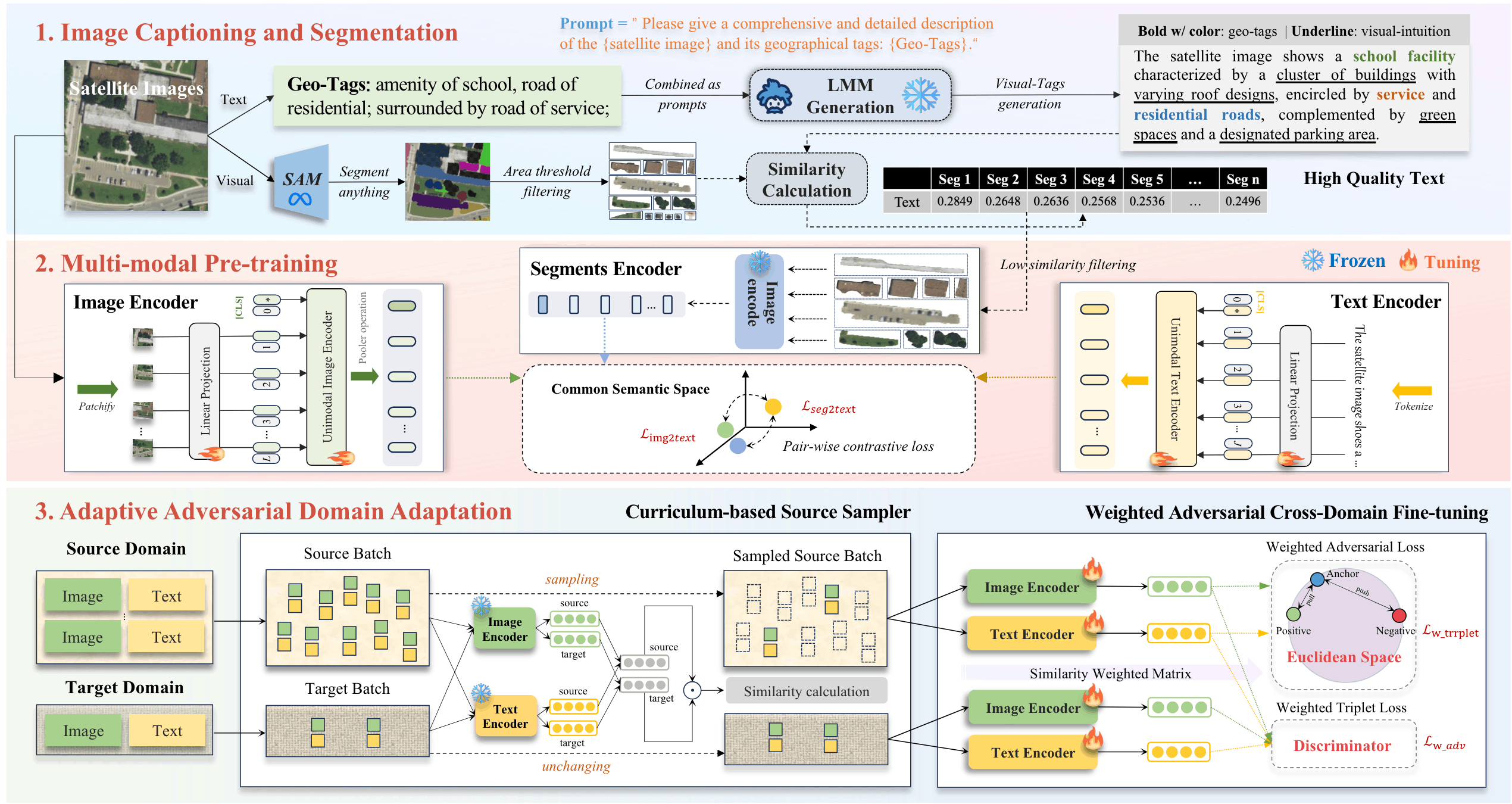
UrbanCross: Enhancing Satellite Image-Text Retrieval with Cross-Domain Adaptation
Siru Zhong, Xixuan Hao, Yibo Yan, Ying Zhang, Yangqiu Song, Yuxuan Liang
MM 2024, Melbourne, Australia Poster
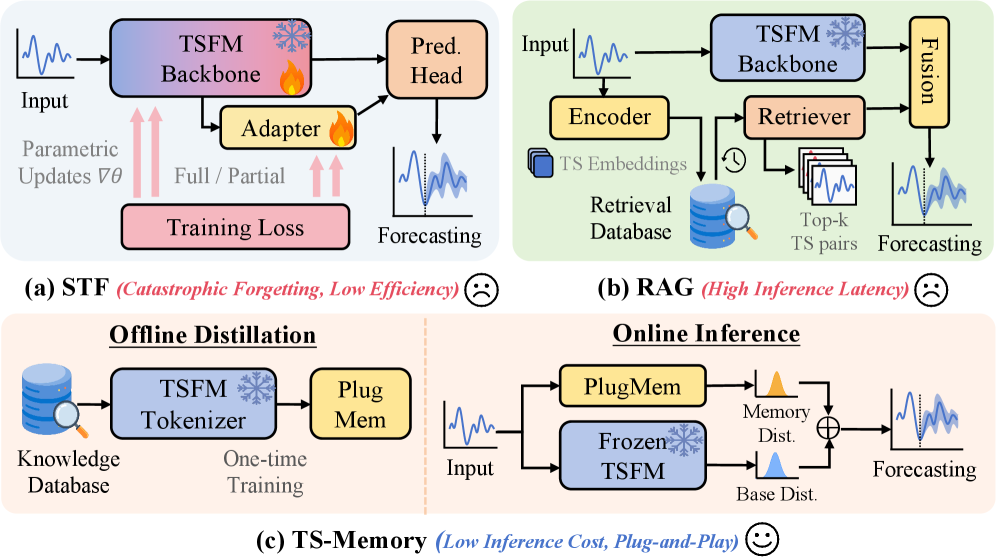
TS-Memory: Plug-and-Play Memory for Time Series Foundation Models
Sisuo Lyu*, Siru Zhong*, Tiegang Chen, Weilin Ruan, Qingxiang Liu, Taiqiang Lv, Qingsong Wen, Raymond Chi-Wing Wong, Yuxuan Liang (* equal contribution)
Under review.
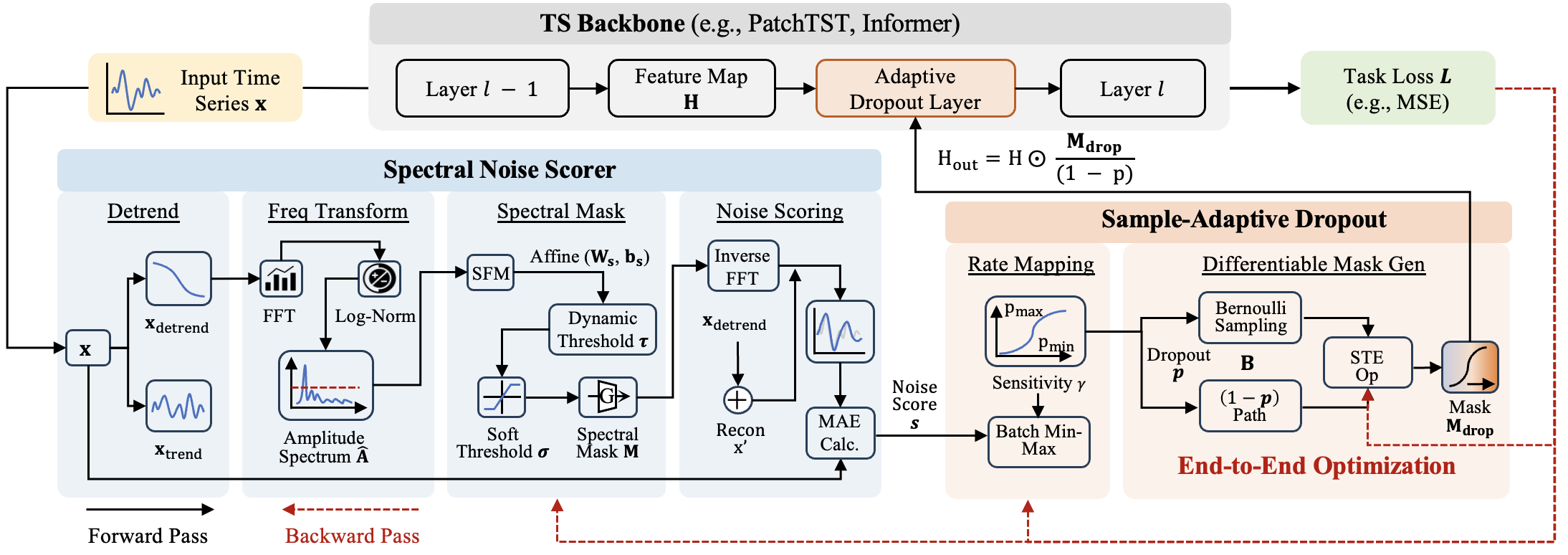
DropoutTS: Sample-Adaptive Dropout for Robust Time Series Forecasting
Siru Zhong, Yiqiu Liu, Zhiqing Cui, Zezhi Shao, Fei Wang, Qingsong Wen, Yuxuan Liang
Under review.
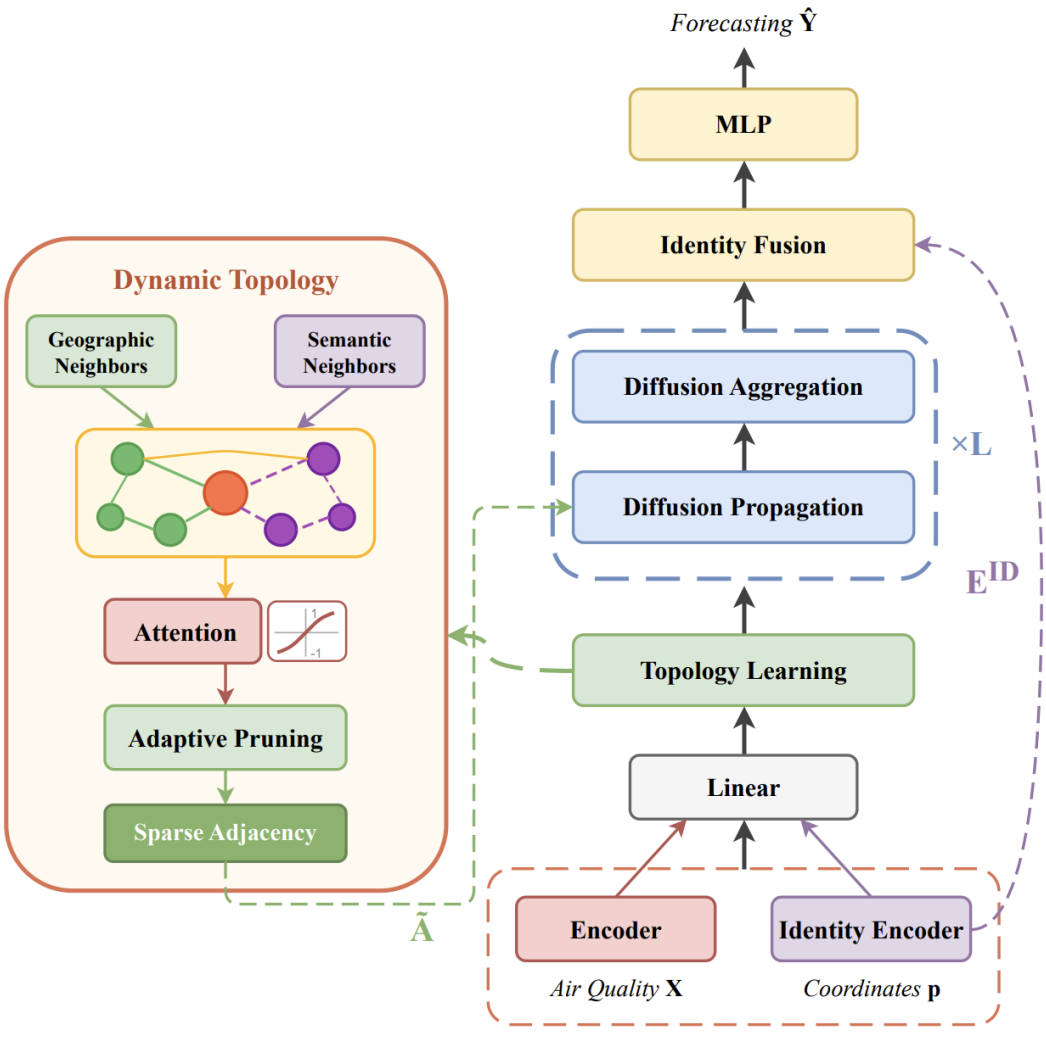
Breaking the Regional Barrier: Inductive Semantic Topology Learning for Worldwide Air Quality Forecasting
Zhiqing Cui*, Siru Zhong*, Ming Jin, Shirui Pan, Qingsong Wen, Yuxuan Liang (* equal contribution)
Under review.
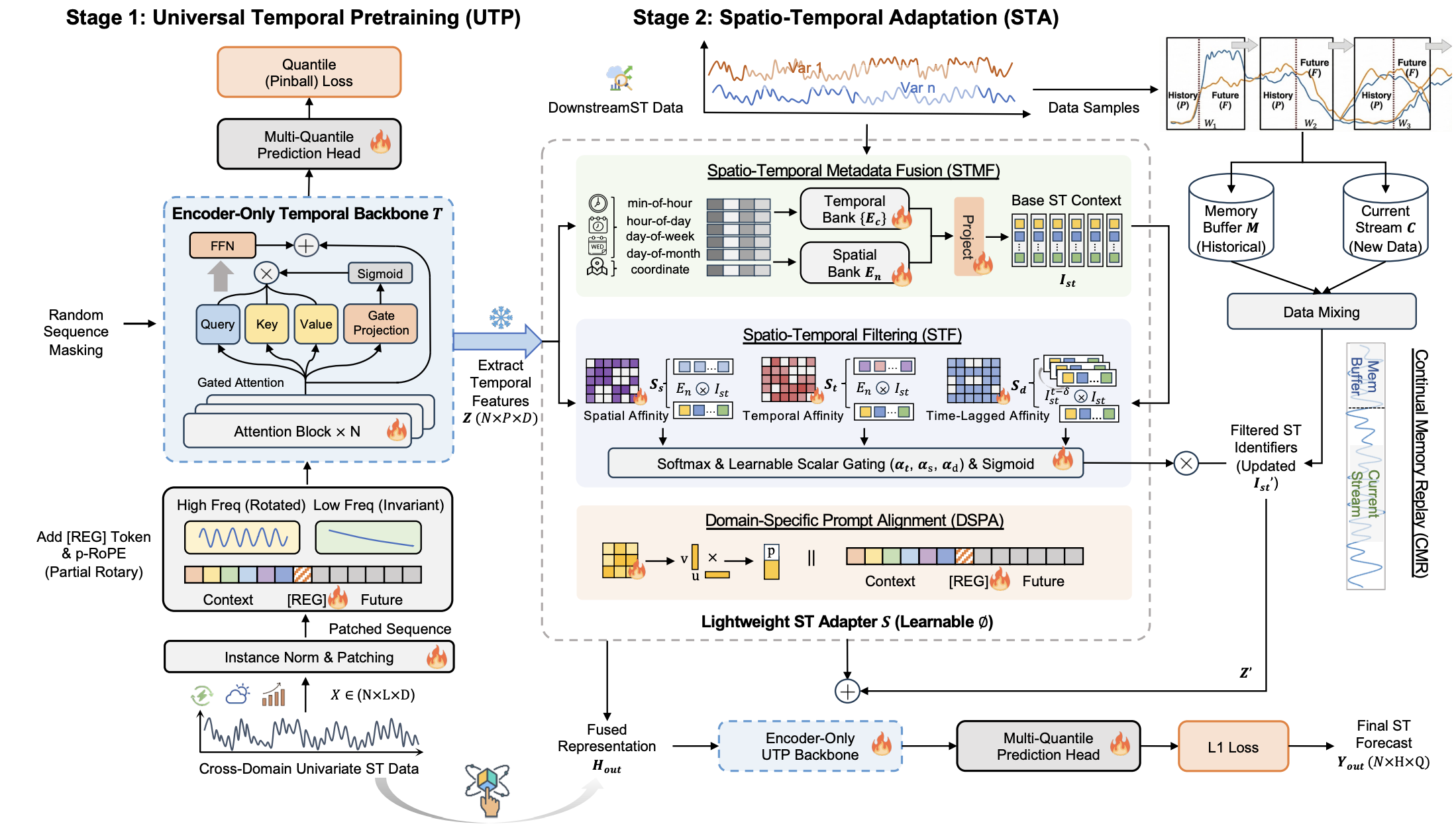
Learning to Factorize and Adapt: A Versatile Approach Toward Universal Spatio-Temporal Foundation Models
Siru Zhong, Junjie Qiu, Yangyu Wu, Yiqiu Liu, Yuanpeng He, Zhongwen Rao, Bin Yang, Chenjuan Guo, Hao Xu, Yuxuan Liang
Under review.
Service
-
Reviewer of KDD 2026 (Datasets and Benchmarks Track, AI4Science Track)
-
PC Member of ACM MM 2026
-
PC Member of AAAI 2026 (Main Track & AISI Track)
-
PC Member of PAKDD 2026
-
Reviewer of IEEE TPAMI
-
Reviewer of IEEE Neurocomputing
-
Reviewer of ICLR 2025, 2026
-
Reviewer of KDD 2026 (Datasets and Benchmarks Track)
-
Reviewer of MM 2025 (Main Track & Dataset Track)
-
Tutorial Organizer of MM4ST@MM2025
-
Web Master of WebST 2025 & UrbComp 2025
Awards
-
Junior Student Track Awardees of DSA Excellent Research Award, HKUST(Guangzhou)2026
-
Runner-Up Prize for DSA Excellent Research Award, HKUST(Guangzhou)2025
-
Best Project Award (1st/15) in Data Science Computing, HKUST(Guangzhou)2023
-
Outstanding Student (Top 10%) in Red Bird Summer Camp, HKUST(Guangzhou)2023
-
iCode Certification of R&D Engineering Competency Evaluation, Tencent2022
-
Silver Award (2nd/12) in Code World Program, Tencent2022
-
Outstanding Student Award (8th/100) in New Employee Training, Tencent2022
-
Outstanding Graduation Thesis Award (Top 2%), HFUT2022
-
First Prize (Top 10) in CSDN Technology Blogger Competition2020
Talks
-
Multi-modal time series analysis
-
Multimodal learning techniques for ST data
-
Learning to Factorize Spatio-Temporal Foundation Models
-
Learning to Factorize Spatio-Temporal Foundation Models
Teaching
-
DSAA60000 Table Representation LearningSpring 2026
-
DSAA2043 Design and Analysis of AlgorithmsFall 2025
-
PLED5001 Communicating Research in EnglishSpring 2025
-
PDEV6800 Introduction to Teaching and Learning in Higher EducationFall 2024